
머신러닝
인공지능개론(정명희) 6주차 강의내용
머신러닝 개요
머신러닝의 정의
‘기계학습’으로도 불리는 인공지능의 한 분야.
인간의 학습 능력을 컴퓨터로 실현하려는 기법.
머신러닝의 역사적 배경
• Arthur Samuel(IBM 연구원)의 체커 프로그램 (1952)
– 세계 최초의 머신러닝 프로그램 중 하나
– 단순한 규칙 기반이 아니라, 경험을 통해 점점 더 나아지는 프로그램
– 휴리스틱 평가 함수(Heuristic Evaluation Function) 사용:
현재 체스판 상태를 숫자로 평가하여 경험을 통해 학습하는 방법 사용
| 연도 | 개발자 | 모델 | 특징 또는 종류 |
|---|---|---|---|
| 1952년 | Arthur Samuel | Checker Program | 최초의 머신러닝 |
| 1957년 | Frank Rosenblatt | Perceptron | 최초의 신경망 모델 |
| 1986년 | Rumelhart 등 | Multilayer Perceptron | Back-propagation 알고리즘 |
| 1986년 | Quinlan | Decision Tree | ID3 |
| 1995년 | Vapnik, Cortes | Support Vector Machine | 이진 분류기 |
머신러닝
머신러닝은 데이터에서 지식을 추출하는 작업.
─ 데이터로부터 유용한 규칙 등을 추출하는 기능.
─ 경험을 통해 데이터 기반으로 학습하고 예측.
프로그래밍하기 어려운 작업의 해결에 주로 활용됨.
머신러닝 학습 개념 예제
1 - 입력과 출력이 여러 개의 데이터 쌍으로 주어짐.
(1, 2), (2, 4), (4, 8), (7, 14), (5, 10), …
2 - 학습 후, 출력이 입력의 2배임을 유추
3 - (3, ?), (8, ?) 등의 질문에 6, 16 등으로 답변
전통적인 프로그래밍과 머신러닝의 차이점
프로그래밍 : 데이터 + 규칙 = 출력
→ 모든 규칙을 작성하며, 규칙이 추가될 경우 유지 관리가 어려움.
머신러닝 : 데이터 + 출력 = 규칙
→ 입출력의 관계를 학습하여 규칙 생성. 시간에 따라 효율 향상.
인공지능 > 머신러닝 > 딥러닝
머신러닝의 활용 분야
| 활용 분야 | 응용 |
|---|---|
| 컴퓨터 비전 | 이미지 분류, 객체 탐지, 얼굴 인식, 문자인식, 물체인식 |
| 자연어 처리 | 기계 번역, 챗봇, 감정 분석, 대화 분석 |
| 음성 인식 | 음성 비서(Bixby, Siri, Alexa), 자동 자막 |
| 추천 시스템 | 유튜브, 넷플릭스, 쇼핑몰 추천, 개인 맞춤식 추천 시스템 |
| 정보 검색 | 스팸 메일 필터링 |
| 로보틱스 & 제어 | 자율주행, 로봇 경로 계획 |
| 의료 AI | 질병 진단, 신약 개발, 환자 모니터링 |
| 금융 AI | 신용평가, 이상거래 탐지, 자동투자 |
머신러닝 알고리즘
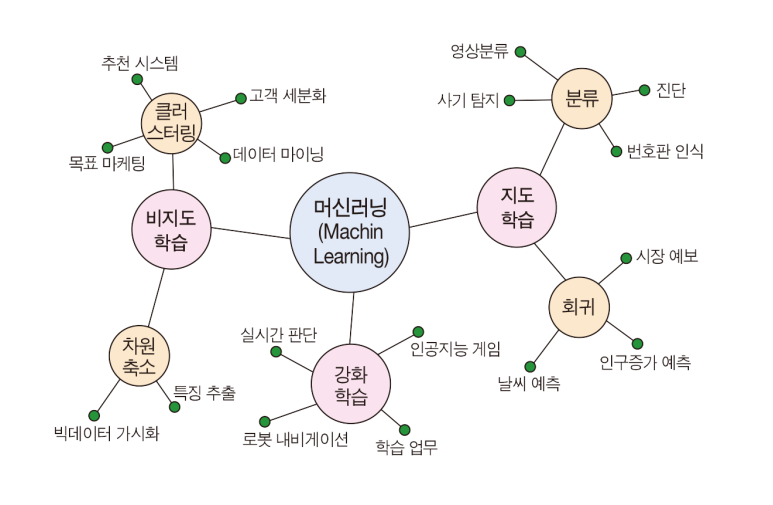
머신러닝의 학습 형태에 따른 분류
지도 학습, 비지도 학습, 강화 학습 등으로 분류.
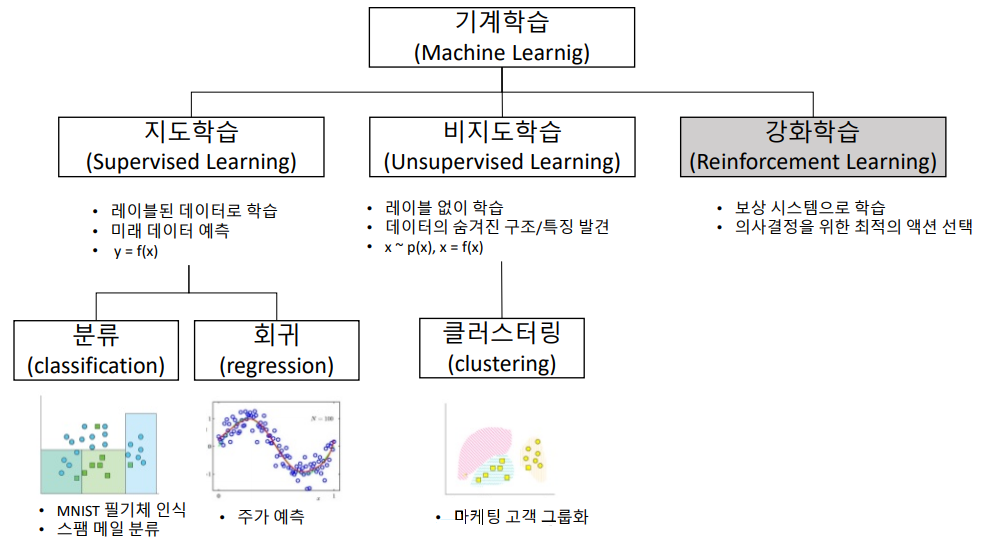
• 지도학습 (Supervised Learning)
입력과 정답(label) 데이터로 학습 → 분류(Classification), 회귀(Regression)
• 비지도학습 (Unsupervised Learning)
정답 없는 데이터에서 패턴 탐색 → 군집화(Clustering), 차원축소(DimensionalityReduction)
• 강화학습 (Reinforcement Learning)
보상을 기반으로 의사결정 전략(policy) 학습 → 게임, 로봇 제어
• 준지도학습 (Semi-Supervised Learning)
라벨링 일부만 활용 → 라벨링 비용 절감
• 자기지도학습 (Self-Supervised Learning)
데이터 자체에서 가상의 라벨을 만들어 학습 → LLM, 멀티모달 AI
기술적 기반
머신러닝을 구현하는 다양한 기법들
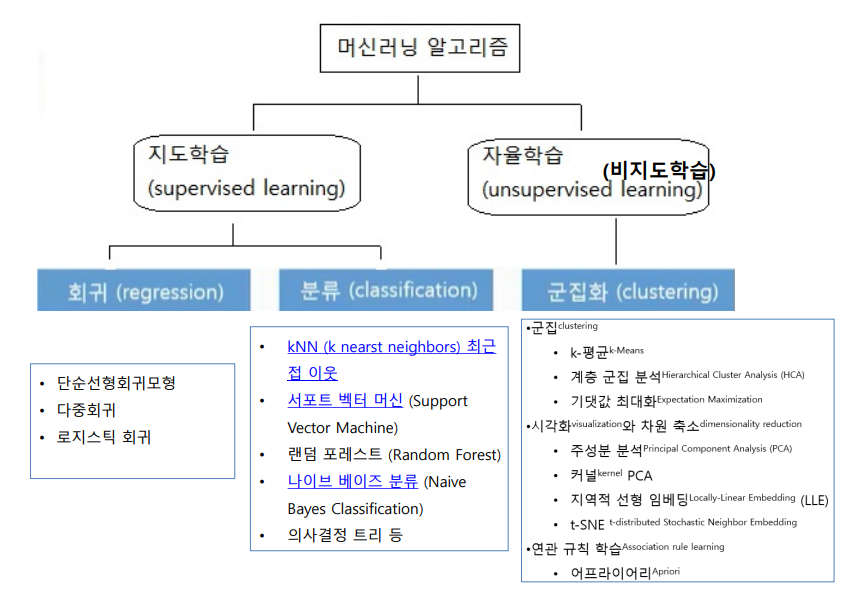
• 전통적 ML 알고리즘
선형회귀, 로지스틱 회귀, k-NN, 결정트리, SVM, 나이브 베이즈
• 앙상블 기법 (Ensemble Methods)
랜덤포레스트(Random Forest), 그래디언트 부스팅(GBM, XGBoost, LightGBM)
• 신경망 및 딥러닝 (Neural Networks & Deep Learning)
MLP, CNN, RNN, Transformer
• 특징학습 & 차원축소
PCA, Autoencoder, t-SNE
• 최적화 & 일반화
경사하강법(GD), 정규화(L1/L2), 드롭아웃(Dropout)
머신러닝의 학습 방법
1. 지도 학습
- 목표 : 새로운 입력이 주어졌을 때 정답 예측
- 주요 알고리즘
- 회귀 : 선형 회귀, 로지스틱 회귀
- 분류 : k-NN, SVM, 결정트리, 신경망
- 회귀 : 선형 회귀, 로지스틱 회귀
- 특징
- 가장 많이 활용되는 방식
- 충분한 라벨링 데이터 필요
- 가장 많이 활용되는 방식
- 응용 사례
- 스팸 메일 필터링, 질병 진단, 주가 예측
2. 비지도 학습
- 정의 : 정답(label) 없이 입력 데이터만으로 패턴 발견
- 목표 : 데이터 구조, 군집, 분포 파악
- 주요 알고리즘
- 군집화(Clustering) : K-means, 계층적 군집
- 차원축소(Dimensionality Reduction) : PCA, t-SNE
- 군집화(Clustering) : K-means, 계층적 군집
- 특징
- 데이터 라벨이 필요 없음
- 패턴/군집 발견에 유용
- 데이터 라벨이 필요 없음
- 응용 사례
- 고객 세분화, 이미지 압축, 이상 탐지
3. 강화학습
- 정의 : 에이전트가 환경과 상호작용하며 보상을 최대화하도록 학습
- 목표 : 최적의 행동 정책 찾기
- 주요 알고리즘
- Q-learning, SARSA, Deep Q-Network(DQN), Policy Gradient
- Q-learning, SARSA, Deep Q-Network(DQN), Policy Gradient
- 특징
- 시퀀스 의사결정에 강점
- 많은 시뮬레이션, 학습 시간 필요
- 시퀀스 의사결정에 강점
- 응용 사례
- 게임, 로봇 제어, 자율주행
4. 준지도학습
- 정의 : 일부만 라벨링된 데이터 + 다수의 비라벨 데이터 활용
- 목표 : 최적의 행동 정책 찾기
- 특징
- 라벨링 비용 절감
- 지도학습과 비지도학습의 장점 결합
- 라벨링 비용 절감
- 응용 사례
- 의료 데이터 분석, 웹 페이지 분류
5. 자기지도학습
- 정의 : 데이터 자체에서 인공적인 라벨을 만들어 학습
- 목표 : 최적의 행동 정책 찾기
- 특징
- 최근 딥러닝/대규모 언어모델에서 핵심
- 대량의 비라벨 데이터 활용 가능
- 최근 딥러닝/대규모 언어모델에서 핵심
- 응용 사례
- LLM, 이미지-텍스트 멀티모달 모델
| 구분 | 입력데이터 | 학습 방식 | 주요 알고리즘 | 대표 응용 |
|---|---|---|---|---|
| 지도학습 | 입력+정답 | 예측 정확도 향상 | 회귀, 분류 | 스팸 필터, 의료 진단 |
| 비지도학습 | 입력만 있음 | 패턴/구조 발견 | 군집화, 차원축소 | 고객 세분화, 이상 탐지 |
| 강화학습 | 상태, 보상 | 보상 최대화 | Q-learning, DQN | 게임, 로봇 제어 |
| 준지도학습 | 일부 라벨 | 라벨+비라벨 혼합 | 전이학습, 그래프 기반 | 의료 데이터 |
| 자기지도학습 | 비라벨 | 데이터 자체 라벨링 | BERT, GPT류 | 자연어처리, 멀티모달 |
지도학습
1. 개념
- 정의 : 입력 데이터(X)와 정답(Label, y)이 함께 주어진 학습 방식.
- 목표 : 새로운 입력에 대해 올바른 정답을 예측하는 함수 f(x)≈y를 학습.
① 장점
- 직관적이고 이해하기 쉬움(입력->출력).
- 경험을 사용하여 성능 기준을 최적화.
- 다양한 유형의 문제 해결(분류, 회귀 등).
- 평가와 비교가 용이.
② 단점
- 출력에 반드시 레이블이 있는 데이터를 사용해야 함.
- 일반화 한계.
- 과적합 위험.
- 데이터 편향 문제.
2. 주요 방법
- 회귀
- 선형 회귀 : 입력 변수와 출력 간의 선형 관계 학습
- 로지스틱 회귀 : 확률 기반 분류 (예: 스팸메일 여부)
- 선형 회귀 : 입력 변수와 출력 간의 선형 관계 학습
- 분류
- k-최근접 이웃 : 가까운 이웃 다수결로 예측
- 서포트 벡터 머신 : 경계를 최대화하는 초평면 분류기
- 결정트리 : 규칙 기반 if-then 분류 -> 직관적 해석 가능
- k-최근접 이웃 : 가까운 이웃 다수결로 예측
- 앙상블 기법
- 랜덤포레스트 : 여러 트리의 투표로 성능 향상
- 그래디언트 부스팅 : 강력한 예측력
- 랜덤포레스트 : 여러 트리의 투표로 성능 향상
- 신경망 기반
- 단층/다층 퍼셉트론 -> 딥러닝의 기본 토대
- 대규모 데이터에서 특히 강력
- 단층/다층 퍼셉트론 -> 딥러닝의 기본 토대
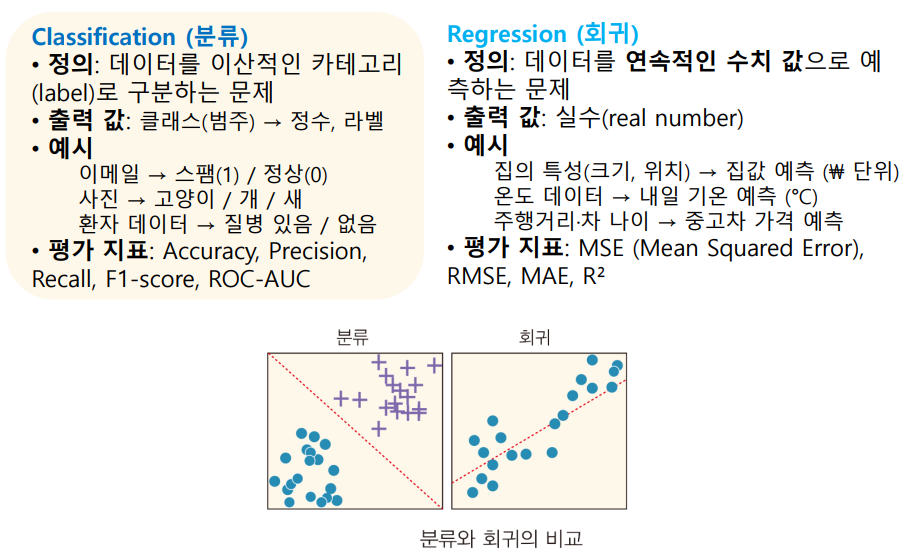
분류
유사한 특성을 가진 데이터들끼리 묶어서 나누는 것.
2개로 분류하는 이항 분류, 그 이상의 다항 분류.
회귀
변수들 사이의 관계를 결정하는 통계적 측정.
하나의 독립 변수를 사용하는 직선 형태의 ‘선형 회귀’.
실제 값과 예측값의 차이의 제곱 합을 최소화하는 회귀 직선을 구하는 방법.
회귀 분석
변수 사이의 회귀에 대해 검정이나 추정을 하는 것.
학습 데이터를 사용하여 출력값을 예측.
회귀 분석
하나 이상의 독립 변수(원인)가 종속 변수(결과)에 미치는 영향을 파악하여 종속 변수의 미래 값을 예측하거나 변수들 간의 관계를 설명하고자 하는 통계분석 기법.
회귀 분석의 주요 목적
① 예측 (Prediction/Forecasting): 독립 변수들의 값을 이용하여 종속 변수의 미래 값을 예측.
② 관계 파악 (Relationship Analysis): 독립 변수와 종속 변수 사이에 어떤 종류의 관계(선형, 비선형 등)가 존재하는지, 각 독립 변수가 종속 변수에 미치는 영향의 방향(양의 상관관계, 음의 상관관계)과 크기 파악.
③ 영향력 파악 (Impact Assessment): 특정 독립 변수가 종속 변수에 통계적으로 유의미한 영향을 미치는지 여부 판단.
회귀분석 기본 개념
∙ 독립변수(independent variable) 또는 설명변수(explanatory variable)
다른 변수에 영향을 주는 원인에 해당하는 변수
∙ 종속변수(dependent variable) 또는 반응변수(response variable)
영향을 받는 결과에 해당하는 변수
∙ 단순회귀분석(simple regression analysis)
독립변수와 종속변수가 각각 하나일 때의 분석
∙ 중회귀분석(multiple regression analysis)
종속변수는 1개이면서 독립변수가 2개 이상일 때의 분석
∙ 단순선형회귀분석(simple linear regression analysis)
독립변수가 1개이고, 독립변수와 종속변수의 관계가 1차 직선인 경우
∙ 다중선형회귀
독립변수가 여러 개이고, 독립과 종속 변수의 관계가 직선인 경우