
알고리즘 성능 평가 방법
인공지능개론(정명희) 9주차 강의내용
알고리즘 성능 평가
정확도 평가 선택
- 지표의 선택은 특정 문제와 우선순위에 따라 결정
- 불균형 데이터셋의 경우
- 정밀도, 재현율, F1 점수, MCC와 같은 지표 중요
- 균형 잡힌 데이터셋의 경우
- 정확도와 AUC가 종종
- *평가 방법을 선택할 때는 애플리케이션의 맥락에서 고려함
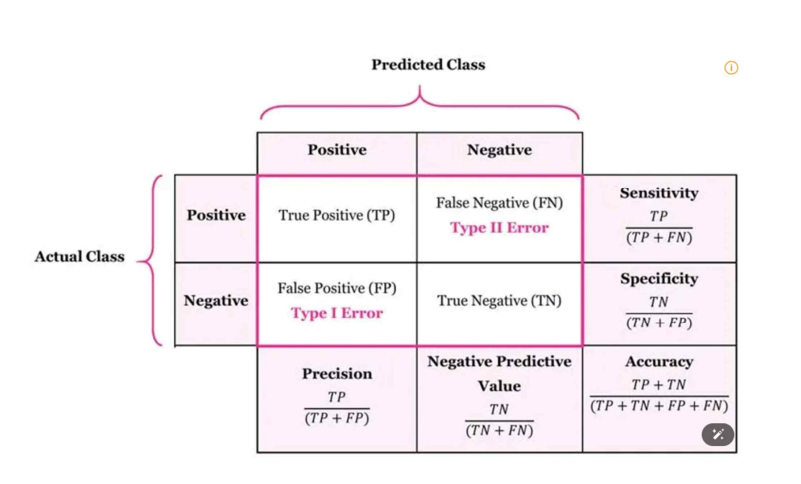
정확도(Accuracy)
- 정의 : 전체 데이터 중에서 모델이 올바르게 예측한 데이터의 비율
- 공식 : $Accuracy=\frac{TP+TN}{TP+FP+FN+TN}$
- 활용 : 데이터셋이 균형 잡혀 있을 때 유용
- 한계 : 데이터 불균형이 있을 경우 왜곡된 결과를 초래할 수 있음
정밀도(Precision)
- 정의 : 모델이 양성으로 예측한 사례 중 실제로 양성인 비율
- 공식 : $Precision=\frac{TP}{TP+FP}$
- 모델이 잘못된 양성 예측을 얼마나 줄였는지를 측정
- 정밀도가 높을수록 양성 예측이 정확함을 의미
재현율(Recall, Sensitivity or True Positive Rate)
- 정의 : 실제 양성 사례 중 모델이 정확히 양성으로 예측한 비율
- 공식 : $Recall=\frac{TP}{TP+FN}$
- 모델이 모든 양성 사례를 얼마나 잘 찾아내는지를 측정
- 재현율이 높을수록 놓치는 양성 사례가 적음 (예: 의료 진단)
F1 점수(F1-Score)
- 정의 : 정밀도와 재현율의 조화 평균으로, 두 지표 간 균형을 측정
- 공식 : $F1-Score=2\cdot\frac{Precision\cdot Recall}{Precision+Recall}$
- 정밀도와 재현율 사이의 균형이 중요한 경우 유용
- 0에서 1 사이 값으로, 1이 최상
특이도(Specificity, True Negative Rate)
- 정의 : 실제 음성 사례 중 모델이 음성으로 정확히 예측한 비율
- 공식 : $Specificity=\frac{TN}{TN+FP}$
- 재현율과 함께 데이터 불균형 상황에서 유용
- 음성 사례를 얼마나 잘 분류하는지 측정
혼동 행렬(Confusion Matrix)
- 정의 : TP, FP, FN, TN 값을 테이블 형식으로 시각화
- 활용 :
모델 성능을 직관적으로 파악
다른 지표를 계산하는 데 유용
회귀모형 평가
NRMSE(Normalized Root Mean Square Error, 정규화된 평균 제곱근 오차)
- NRMSE는 회귀 모델의 성능을 평가하기 위해 사용되는 지표
- RMSE(Root Mean Square Error)를 정규화하여 데이터의 스케일에 독립적인 척도로 만듦
- 이를 통해 서로 다른 스케일의 데이터셋 간 성능 비교 용이
- 공식 :
- $RMSE=\sqrt{\frac{1}{N}\sum_{i=1}^{N}(y_{i}-\hat{y}_{i})^{2}}$
- $NRMSE = \frac{RMSE}{\text{정규화 인자}}$
- 변수 :
- $y_{i}$ : 관측값
- $\hat{y}_{i}$ : 예측값
- N : 데이터 포인트의 총 개수
- 해석 :
- 0: 완벽한 예측(오차 없음)
- 0에 가까움: 관측값과 예측값이 매우 유사
- 값이 클수록: 정규화 인자 대비 큰 오차를 의미
MAPE (Mean Absolute Percentage Error, 평균 절대 백분율 오차)
- 회귀 모델 평가에서 자주 사용되는 지표로, 예측값과 실제값의 차이를 백분율로 표현하여 모델의 예측 성능 측정
- 공식 : $MAPE=\frac{1}{N}\sum_{i=1}^{N}|\frac{y_{i}-\hat{y}{i}}{y{i}}|\times100$
- 변수 :
- $y_{i}$ : 실제값
- $\hat{y}_{i}$ : 예측값
- N : 데이터 포인트의 총 개수
- 해석 :
- $MAPE=0\%$ : 완벽한 예측(오차 없음)
- 낮은 값: 예측이 실제값에 가깝다는 것을 의미
- 높은 값: 모델이 큰 오차를 가지고 있다는 것을 나타냄
- 결과는 백분율로 표현되며, MAPE가 5%라면 모델의 예측값은 실제값에서 평균적으로 5% 정도 벗어나 있다는 의미